




Tech Issue 01 - 대규모 딥러닝 고속처리를 위한 분산 딥러닝 플랫폼 기술
Tech Issue 01은 공공기관의 연구성과 확산을 위해 국가과학기술연구회(NST)와 공동으로 우수 공공기술을 선별하여 게재하고 있습니다.

▲ 글. 안신영 책임연구원
한국전자통신연구원 초성능컴퓨팅연구본부
딥러닝이란 기계(컴퓨터)가 실세계를 학습할 수 있도록 사람의 신경세포를 모사한 인공신경망(Artificial Neural Network)을 빅데이터를 이용하여 학습시키는 기술로 이미지 인식, 음성 인식, 자연어 처리의 발전에 기여하며 주목받았으며, 점차 다양한 분야로 그 영역이 확장되고 있다.
딥러닝의 대상이 되는 응용(예: 이미지 인식)이 복잡할수록 학습되는 내용(모델 크기)은 증가하게 되며, 충실한(정확도가 높은) 학습을 위해서는 더 많은 데이터를 학습해야 한다.
즉 복잡한 응용일수록 더 높은 정확도를 요구하는 딥러닝 모델(응용)을 학습하기 위해서는 더 많은 양과 더 높은 해상도의 학습 데이터를 요구하며, 이런 모델을 학습하기 위해서는 더 많은 계산량을 빠르게 처리할 수 있는 고성능 컴퓨팅 시스템이 필수적이다.
고성능 컴퓨팅 시스템이란 과거에는 다수의 중앙처리장치(CPU)와 대규모 메모리를 가지는 단일 컴퓨터 시스템을 의미하였다면, 지금은 다수의 비용효율적인 고성능 컴퓨터를 고속 네트워크로 연결하여 구성하는 컴퓨팅 클러스터를 의미한다.
고성능 컴퓨팅 시스템을 이용하여 대규모 딥러닝 모델을 학습하기 위해서는 분산 병렬처리가 필요하다.
분산처리란 계산을 나누어 처리하고 최종적으로 나누어 처리된 결과를 통합하는 작업을 하는 컴퓨팅 방식이고, 병렬처리란 분산처리 방식으로 계산을 나누어 가진 다수의 컴퓨터가 주기적으로 통신을 수행하면서 계산하고 최종적으로 결과를 통합하여 얻는 방식이다.
즉 병렬처리는 분산처리의 부분집합이라 할 수 있다. 그러나 분산처리와 병렬처리의 가장 큰 차이점은 계산에 참여하는 컴퓨터 간에 계산중에 통신(또는 데이터 동기화)이 빈번하게 발생하느냐는 것이다.
분산 딥러닝은 분산병렬처리의 특성을 가진다.
일반적인 과학계산용 병렬처리 응용이 통신주기가 매우 짧고 레이턴시(Latency)가 중요하다면, 분산 딥러닝은 전통적인 과학계산용 병렬처리 응용보다는 통신주기가 상대적으로 길고 높은 대역폭이 중요하다.
분산 딥러닝은 많은 자료를 이해하는 과제를 수행하는 모둠학습을 상상하면 쉽게 이해할 수 있다.
혼자서 모든 자료를 읽고 이해하려면 너무 오래 걸리는 과제가 있다면, 여러 학생이 자료를 나누어 학습하고(분산 딥러닝의 계산에 해당), 각자 학습한 내용을 상호간에 발표하는(분산 딥러닝의 통신에 해당) 시간을 반복함으로써 더 빠르게 많은 자료를 이해할 수 있다.
대규모 딥러닝 분산 학습에서의 문제점은 모둠학습에서 각 학생이 학습한 내용을 서로에게 알려주는 시간에 해당하는 학습된 내용의 상호 교환 시 발생하는 통신 병목 문제이다.
예를 들어 가장 많이 활용되는 이미지 분류 모델중 하나인 Resnet 50 모델의 분산 딥러닝 시에 발생하는 통신량을 계산해 보겠다.
딥러닝 트레이닝은 적당한 규모의 학습 데이터(미니배치)를 단위 학습(계산)하고 그 학습된 내용(파라미터라고 부름)를 분산 학습에 참여하는 컴퓨터들 간에 교환하는 과정을 반복하는데, Resnet 50 모델의 경우 이 파라미터의 크기가 약 100MB이다.
만약 파라미터 서버를 이용하는 분산 딥러닝에 참여하는 컴퓨터의 수를 16대라고 가정하면, 각 컴퓨터가 각자 학습한 파라미터를 파라미터 서버로 한 번 보내고, 통합된 파라미터를 한 번 받아야 하므로 단위 학습마다 컴퓨터 당 200MB의 통신 트래픽이 발생하고, 총 3.2GB의 통신량이 단위 학습(계산) 주기마다 발생한다.
Resnet 50 모델의 경우 딥러닝 프레임워크(또는 플랫폼)마다 계산 주기는 조금씩 편차가 있을 수 있으나 단위학습에 걸리는 계산 시간을 200㎳라고 가정하면, 초당 16GB의 통신트래픽(3.2GB*1sec/200㎳)을 처리할 수 있어야 한다.
이는 통신 속도의 단위인 bps(bit per second)로 환산하면 128Gbps의 고속 통신 대역폭을 요구한다.
이와 같은 대규모 트래픽 발생은 다수의 컴퓨터를 이용하여 빠르게 대규모 딥러닝 모델을 학습하려는 응용에 있어 치명적인 성능 저하 요인이다.
딥러닝 모델의 분산 학습 시에 발생하는 통신 병목을 해결하는 방법으로는 통신 대역폭을 높이는 방법들과 파라미터 통신량을 줄이는 방법들이 있다.
기존 통신 대역폭을 높이는 방법으로는 더 빠른 통신 네트워크를 구비한 고속 서버(예: NVIDIA DGX-1/2)를 구매하는 방식이 있고, 파라미터 통신량을 줄이는 기존 방법으로는 파라미터를 압축하는 방법과 통신할 파라미터를 선택하는 방법, 그리고 파라미터 업데이트 주기를 변경(늘리는)하는 방식이 있다.
한국전자통신연구원에서는 이 통신 병목을 해결하기 위해 1) TCP/IP의 통신 프로토콜 병목 제거 방법, 2) 통신량을 다수의 서버로 분산하는 방법, 3) 하이브리드 딥러닝 파라미터 업데이트 방법을 개발하였다.
첫 번째로 TCP/IP의 통신 프로토콜 병목 제거는 소프트 메모리 박스(Soft Memory Box, 이하 SMB)라 불리는 공유 메모리 버퍼 프레임워크를 개발함으로써 해결하였다.
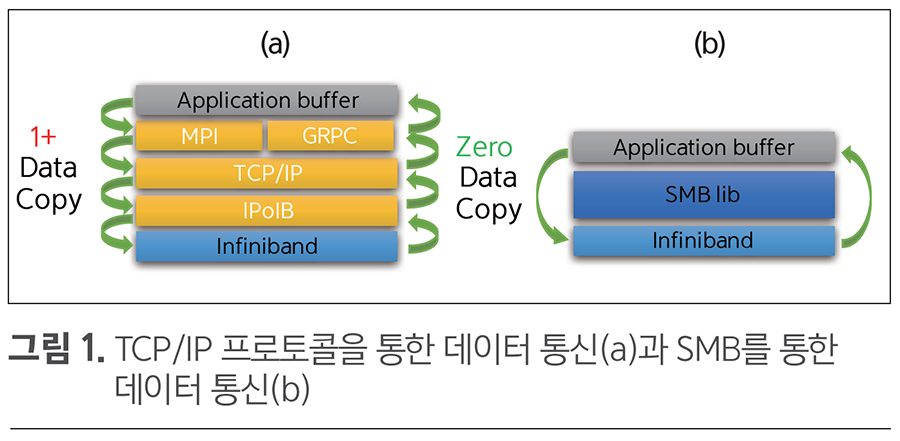
그림 1의 (a)를 보면 TCP/IP 통신 프로토콜을 이용하는 경우에는 응용프로그램의 버퍼에서 다수의 프로토콜 스택을 타고 내려오면서 다수의 데이터 복사가 일어난다.
(a)는 송신측만을 보여주며, 수신측에서는 역과정을 반복해야 한다.
그러나 그림 1의 (b)를 보면 SMB 라이브러리는 TCP/IP 프로토콜 스택을 이용하지 않고, 인피니밴드 네트워크가 제공하는 RDMA(Remote Direct Memory Access) 기능을 이용하여 원격 메모리 버퍼에 직접 데이터를 읽고 쓰기 때문에 송수신측의 프로토콜 처리 오버헤드가 없어 더 빠른 파라미터 통신을 지원한다.
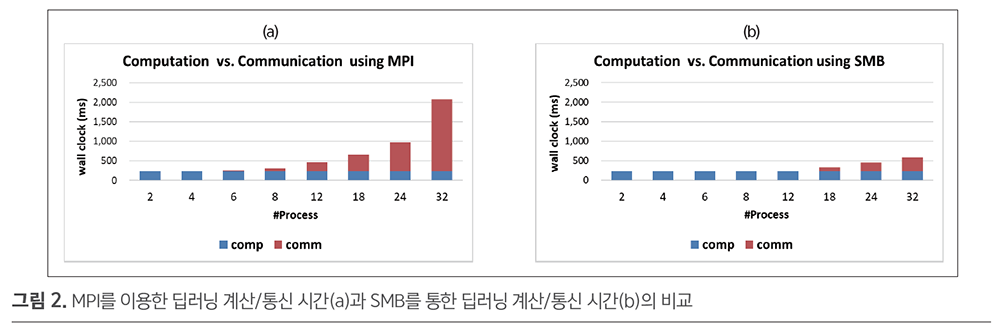
그림 2는 딥러닝 분산 트레이닝 시에 분산 프로세스의 수를 늘려감에 따라 측정된 계산/통신 시간을 비교한 그래프로, (a) TCP/IP 기반의 MPI(Message Passing Interface)를 이용한 경우보다, (b) SMB를 이용한 경우에서 통신 오버헤드를 획기적으로 감축하는 것을 확인할 수 있다.
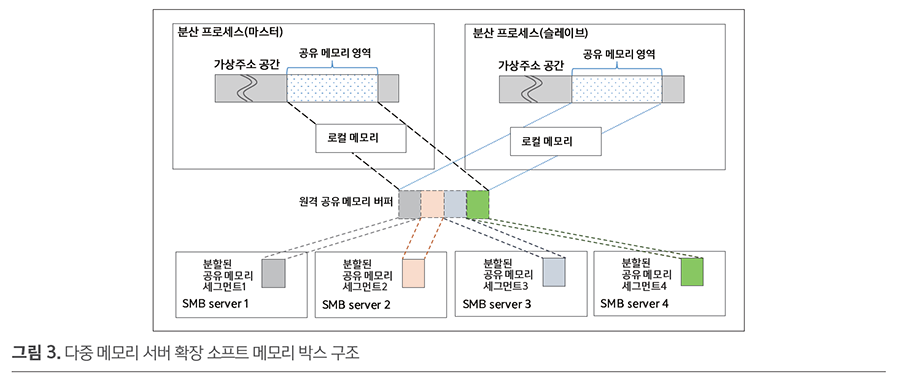
두 번째로 통신량을 다수의 서버로 분산하는 방식은 그림 3과 같이 다수의 공유 메모리 서버들의 메모리를 모아서 가상의 통합 공유 메모리를 제공하는 기능으로, 원격 공유 메모리를 제공하는 서버의 수를 늘려감에 따라 할당 가능한 공유메모리의 크기가 증가할 뿐 아니라 통신 대역폭은 메모리 서버 수에 비례하여 늘어나게 된다.
이와 같은 통신 대역폭의 확장은 분산처리에 참여하는 컴퓨터의 수를 증가시킴으로써 더 빠르게 딥러닝 분산 학습을 가능하게 한다.
마지막으로 하이브리드 딥러닝 파라미터 업데이트 방식은 기존의 분산 딥러닝 파라미터 업데이트 방식인 동기식 파라미터 업데이트 방법과 비동기적 파라미터 방식을 2단계로 혼합한 방식으로, 하나의 컴퓨터 안에 있는 GPGPU 간에는 시스템버스를 통해 동기식으로 파라미터를 1차 업데이트하고, 컴퓨터들 간에는 외부 고속네트워크를 통해 비동기적으로 파라미터를 2차 업데이트하는 방식이다.
이처럼 하면 동일 컴퓨터 안의 GPGPU 간 파라미터 통신량이 그 컴퓨터의 시스템 버스를 통해 교환되므로 외부 네트워크로 송수신해야 하는 통신량이 감소한다.
한국전자통신연구원에서는 앞서 설명된 3가지 기술을 기반으로 소프트 메모리 박스, ETRI-Caffe, ETRI-Tensorflow의 3종 소프트웨어를 개발하였다.
소프트 메모리 박스는 분산 딥러닝용 파라미터의 고속 통신을 위한 분산 공유 메모리 버퍼(Shared Memory Buffer)를 제공한다.
SMB는 Infiniband 네트워크 기반 소프트웨어로 다수 서버들의 메모리를 통합하여 딥러닝 파라미터 통신을 위한 버퍼로 제공한다.
ETRI-Caffe(SW)는 BVLC/NVIDIA Caffe를 다중 머신 지원용으로 확장한 분산 딥러닝 소프트웨어이다.
분산 프로세스의 실행 관리를 위해 MPI 방식을 이용하나, 분산 딥러닝 프로세스 간 파라미터 통신을 위해서는 소프트 메모리 박스의 공유 메모리를 이용한다.
ETRI-Caffe는 BVLC/NVIDIA Caffe 모델을 수정 없이 훈련할 수 있으며, 데이터 병렬 비동기 분산 학습을 지원한다.
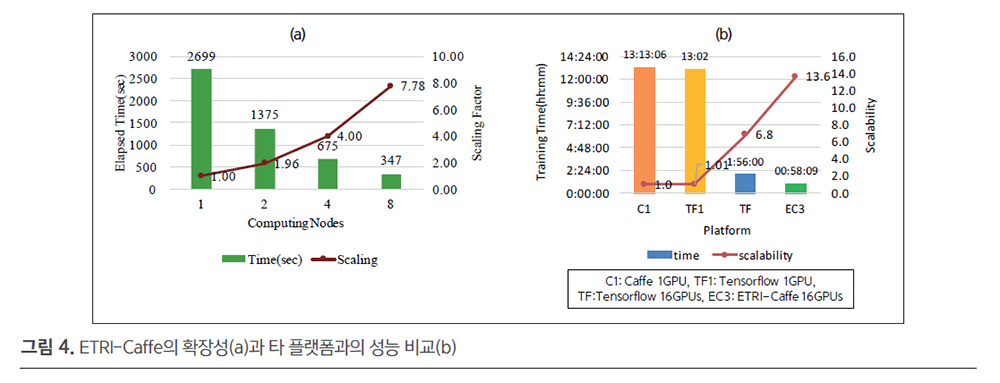
ETRI-Caffe(v3.0)는 그림 4의 (a)와 같이 1 노드에서 8 노드로 스케일 아웃했을때 약 97%의 확장효율을 제공하며(8노드 7.78배 속도 향상, Resnet-50, 10,000 iteration 기준), 그림 4의 (b)와 같이 Inception_bn 모델의 경우 1GPU에서 16GPU로 스케일 아웃했을 때 NVIDIA Caffe(1GPU) 대비 13.6배 빠른 학습이 가능하며, 이는 동일 모델을Tensorflow로 학습할 때와 비교해도 2배 빠른 학습성능을 달성한다.
ETRI-TensorFlow는 보다 빠른 딥러닝 학습을 위하여 Google의 TensorFlow를 소프트 메모리 박스가 제공하는 공유 메모리를 기반으로 확장한 분산 딥러닝 프레임워크로, TensorFlow 모델 호환을 제공하며, CNN, RNN 및 그 외 DNN 모델을 지원한다.
ETRITensorFlow는 데이터 병렬과 모델 병렬 비동기식 분산학습을 지원한다.
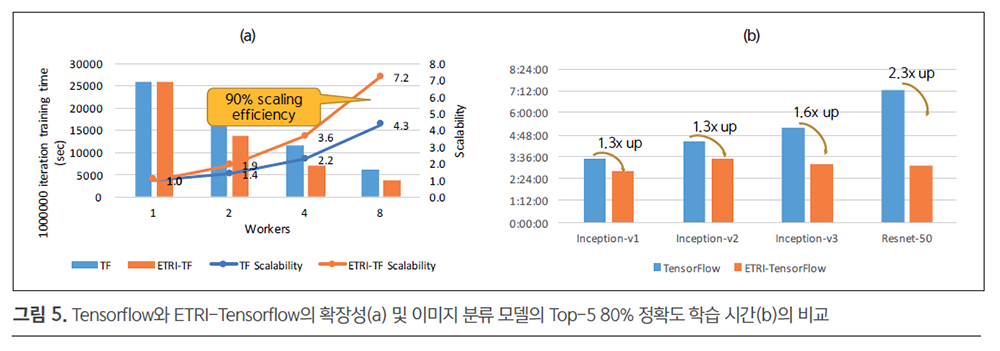
그림 5의 (a)를 보면 ETRITensorflow가 Tensorflow보다 35% 이상 더 우수한 확장 효율을 보이며(90% 확장효율 달성), 그림 5의 (b)를 보면 다양한 모델의 80% 정확도 학습시간에서도 Tensorflow 대비 1.3~2.3배 더 빠르게 학습을 완료하는 것을 확인할 수 있다.
본 연구팀은 분산 딥러닝 플랫폼과 관련하여 SCI-E 및 최우수학술대회 논문을 포함해 총 5편의 국제 논문을 게재 및 발표하였으며, 특허는 4건 출원하였다.
한국전자통신연구원은 이종의 GPU 기반 고성능 컴퓨팅시스템에서 최고의 분산처리 성능을 달성하는 기술을 통해 국내 기업의 딥러닝 분산학습 기술 및 제품 개발을 지원함으로써, 국내 기업이 적시에 인공지능 기술을 개발하여 시장을 선도할 수 있는 기술 경쟁력을 확보하는 데 기여하고자 한다.